|
I am a staff research scientist at Google Research, where I work on computer vision and machine learning. At Google I've worked on Lens Blur, HDR+, Jump, Portrait Mode, and Glass. I did my PhD at UC Berkeley, where I was advised by Jitendra Malik and funded by the NSF GRFP. I did my bachelors at the University of Toronto. Email / CV / Biography / Google Scholar / Social |

|
|
I'm interested in computer vision, machine learning, optimization, and image processing. Much of my research is about inferring the physical world (shape, depth, motion, paint, light, colors, etc) from images. Representative papers are highlighted. |

|
Ben Mildenhall*, Pratul Srinivasan*, Matthew Tancik*, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng arXiv, 2020 project page / arXiv / video / code Training a tiny non-convolutional neural network to reproduce a scene using volume rendering achieves photorealistic view synthesis. |
 
|
Xuaner (Cecilia) Zhang, Jonathan T. Barron, Yun-Ta Tsai, Rohit Pandey, Xiuming Zhang, Ren Ng, David E. Jacobs SIGGRAPH, 2020 project page / video Networks can be trained to remove shadows cast on human faces and to soften harsh lighting. |
 
|
Charles Herrmann, Richard Strong Bowen, Neal Wadhwa, Rahul Garg, Qiurui He, Jonathan T. Barron, Ramin Zabih CVPR, 2020 arXiv Machine learning can be used to train cameras to autofocus (which is not the same problem as "depth from defocus"). |
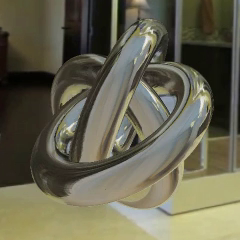
|
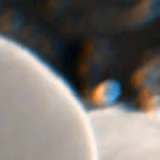
Pratul Srinivasan*, Ben Mildenhall*, Matthew Tancik, Jonathan T. Barron, Richard Tucker, Noah Snavely CVPR, 2020 project page / arXiv / video We predict a volume from an input stereo pair that can be used to calculate incident lighting at any 3D point within a scene. |
 
|
Orly Liba, Kiran Murthy, Yun-Ta Tsai, Timothy Brooks, Tianfan Xue, Nikhil Karnad, Qiurui He, Jonathan T. Barron, Dillon Sharlet, Ryan Geiss, Samuel W. Hasinoff, Yael Pritch, Marc Levoy SIGGRAPH Asia, 2019 project page By rethinking metering, white balance, and tone mapping, we can take pictures in places too dark for humans to see clearly. |
 
|
Akshay Srivatsan, Jonathan T. Barron, Dan Klein, Taylor Berg-Kirkpatrick EMNLP, 2019 (Oral Presentation) Variational auto-encoders can be used to disentangle a characters style from its content. |
|
Rahul Garg, Neal Wadhwa, Sameer Ansari,, Jonathan T. Barron ICCV, 2019 (Oral Presentation) code / bibtex Considering the optics of dual-pixel image sensors improves monocular depth estimation techniques. |
 
|
Tiancheng Sun, Jonathan T. Barron, Yun-Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, Ravi Ramamoorthi SIGGRAPH, 2019 video / press / bibtex Training a neural network on light stage scans and environment maps produces an effective relighting method. |
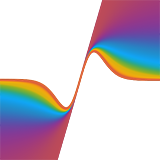 
|
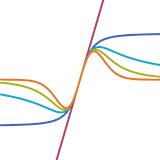
Jonathan T. Barron CVPR, 2019 (Oral Presentation, Best Paper Award Finalist) arxiv / supplement / video / talk / slides / tensorflow code / pytorch code / reviews / bibtex A single robust loss function is a superset of many other common robust loss functions, and allows training to automatically adapt the robustness of its own loss. |
 
|
Pratul P. Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, Noah Snavely CVPR, 2019 (Oral Presentation, Best Paper Award Finalist) supplement / video / bibtex View extrapolation with multiplane images works better if you reason about disocclusions and disparity sampling frequencies. |
 
|
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Jonathan T. Barron CVPR, 2019 (Oral Presentation) arxiv / project page / code / bibtex We can learn a better denoising model by processing and unprocessing images the same way a camera does. |
 
|
Tim Brooks, Jonathan T. Barron CVPR, 2019 (Oral Presentation) arxiv / supplement / project page / video / code / bibtex Frame interpolation techniques can be used to train a network that directly synthesizes linear blur kernels. |
|
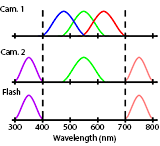
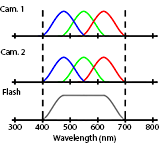
Jian Wang, Tianfan Xue, Jonathan T. Barron Jiawen Chen ICCP, 2019 By making one camera in a stereo pair hyperspectral we can multiplex dark flash pairs in space instead of time. |
 
|
Julien Valentin, Adarsh Kowdle, Jonathan T. Barron, Neal Wadhwa, and others SIGGRAPH Asia, 2018 bibtex Depth cues from camera motion allow for real-time occlusion effects in augmented reality applications. |
 
|
Neal Wadhwa, Rahul Garg, David E. Jacobs, Bryan E. Feldman, Nori Kanazawa, Robert Carroll, Yair Movshovitz-Attias, Jonathan T. Barron, Yael Pritch, Marc Levoy SIGGRAPH, 2018 arxiv / blog post / bibtex Dual pixel cameras and semantic segmentation algorithms can be used for shallow depth of field effects. This system is the basis for "Portrait Mode" on the Google Pixel 2 smartphones |
 
|
Pratul P. Srinivasan, Rahul Garg, Neal Wadhwa, Ren Ng, Jonathan T. Barron CVPR, 2018 code / bibtex Varying a camera's aperture provides a supervisory signal that can teach a neural network to do monocular depth estimation. |
 
|
Ben Mildenhall, Jonathan T. Barron, Jiawen Chen, Dillon Sharlet, Ren Ng, Robert Carroll CVPR, 2018 (Spotlight) supplement / code / bibtex We train a network to predict linear kernels that denoise noisy bursts from cellphone cameras. |
|
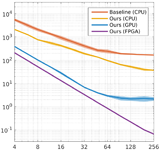
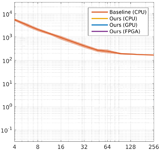
Amrita Mazumdar, Armin Alaghi, Jonathan T. Barron, David Gallup, Luis Ceze, Mark Oskin, Steven M. Seitz High-Performance Graphics (HPG), 2017 project page A reformulation of the bilateral solver can be implemented efficiently on GPUs and FPGAs. |
 
|
Michaël Gharbi, Jiawen Chen, Jonathan T. Barron, Samuel W. Hasinoff, Frédo Durand SIGGRAPH, 2017 project page / video / bibtex / press By training a deep network in bilateral space we can learn a model for high-resolution and real-time image enhancement. |
 
|
Jonathan T. Barron, Yun-Ta Tsai, CVPR, 2017 supplement / video / bibtex / code / output / blog post / press Color space can be aliased, allowing white balance models to be learned and evaluated in the frequency domain. This improves accuracy by 13-20% and speed by 250-3000x. This technology is used by Google Pixel, Google Photos, and Google Maps. |
|
Robert Anderson, David Gallup, Jonathan T. Barron, Janne Kontkanen, Noah Snavely, Carlos Hernández, Sameer Agarwal, Steven M Seitz SIGGRAPH Asia, 2016 supplement / video / bibtex / blog post Using computer vision and a ring of cameras, we can make video for virtual reality headsets that is both stereo and 360°. This technology is used by Jump. |
|
Samuel W. Hasinoff, Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T. Barron, Florian Kainz, Jiawen Chen, Marc Levoy SIGGRAPH Asia, 2016 project page / supplement / bibtex Mobile phones can take beautiful photographs in low-light or high dynamic range environments by aligning and merging a burst of images. This technology is used by the Nexus HDR+ feature. |
 
|
Jonathan T. Barron, Ben Poole ECCV, 2016 (Best Paper Honorable Mention) arXiv / supplement / bibtex / video (they messed up my slides, use →) / keynote (or PDF) / code / depth super-res results / reviews Our solver smooths things better than other filters and faster than other optimization algorithms, and you can backprop through it. |
 
|
Stephen DiVerdi, Jonathan T. Barron WACV, 2016 bibtex Standard techniques for stereo calibration don't work for cheap mobile cameras. |
 
|
CVPR, 2016 Liang-Chieh Chen, Jonathan T. Barron, George Papandreou, Kevin Murphy, Alan L. Yuille bibtex / project page / code By integrating an edge-aware filter into a convolutional neural network we can learn an edge-detector while improving semantic segmentation. |
 
|
Jonathan T. Barron ICCV, 2015 supplement / bibtex / video (or mp4) By framing white balance as a chroma localization task we can discriminatively learn a color constancy model that beats the state-of-the-art by 40%. |

|
Evan Shelhamer, Jonathan T. Barron, Trevor Darrell ICCV Workshop, 2015 bibtex The monocular depth estimates produced by fully convolutional networks can be used to inform intrinsic image estimation. |

|
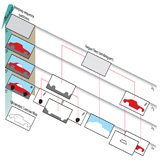
Jonathan T. Barron, Andrew Adams, YiChang Shih, Carlos Hernández CVPR, 2015 (Oral Presentation) abstract / supplement / bibtex / talk / keynote (or PDF) By embedding a stereo optimization problem in "bilateral-space" we can very quickly solve for an edge-aware depth map, letting us render beautiful depth-of-field effects. This technology is used by the Google Camera "Lens Blur" feature. |
|
Jordi Pont-Tuset, Pablo Arbeláez, Jonathan T. Barron, Ferran Marqués, Jitendra Malik TPAMI, 2017 project page / bibtex / fast eigenvector code We produce state-of-the-art contours, regions and object candidates, and we compute normalized-cuts eigenvectors 20× faster. This paper subsumes our CVPR 2014 paper. |

|
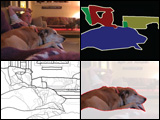
We present SIRFS, which can estimate shape, chromatic illumination, reflectance, and shading from a single image of an masked object. This paper subsumes our CVPR 2011, CVPR 2012, and ECCV 2012 papers. |
|
Pablo Arbeláez, Jordi Pont-Tuset, Jonathan T. Barron, Ferran Marqués, Jitendra Malik CVPR, 2014 project page / bibtex This paper is subsumed by our journal paper. |
|
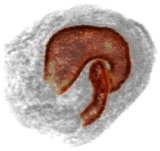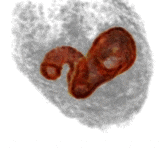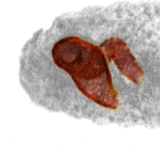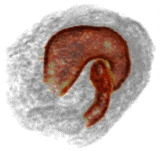
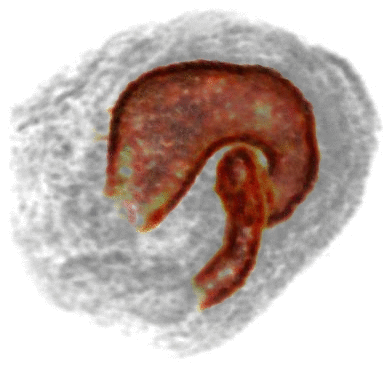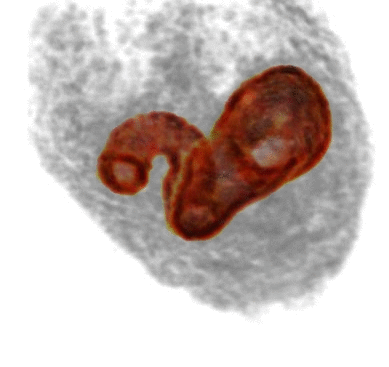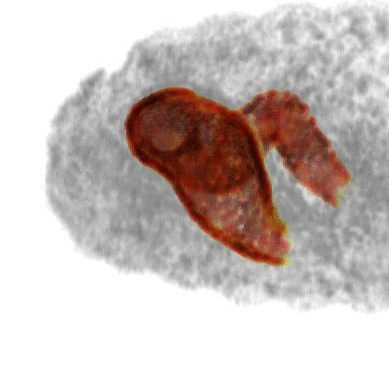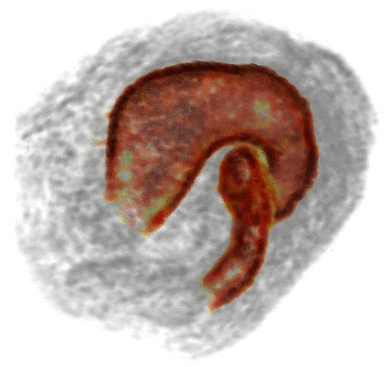
Jonathan T. Barron, Pablo Arbeláez, Soile V. E. Keränen, Mark D. Biggin, David W. Knowles, Jitendra Malik ICCV, 2013 supplement / poster / bibtex / video 1 (or mp4) / video 2 (or mp4) / code & data We present a technique for efficient per-voxel linear classification, which enables accurate and fast semantic segmentation of volumetric Drosophila imagery. |

|
Hao Li, Etienne Vouga, Anton Gudym, Linjie Luo, Jonathan T. Barron, Gleb Gusev SIGGRAPH Asia, 2013 video / shapify.me / bibtex Our system allows users to create textured 3D models of themselves in arbitrary poses using only a single 3D sensor. |
  |
Jonathan T. Barron, Jitendra Malik CVPR, 2013 (Oral Presentation) supplement / bibtex / talk / keynote (or powerpoint, PDF) / code & data By embedding mixtures of shapes & lights into a soft segmentation of an image, and by leveraging the output of the Kinect, we can extend SIRFS to scenes.
|

|
Kevin Karsch, Zicheng Liao, Jason Rock, Jonathan T. Barron, Derek Hoiem CVPR, 2013 supplement / bibtex Boundary cues (like occlusions and folds) can be used for shape reconstruction, which improves object recognition for humans and computers. |

 |
Jonathan T. Barron, Jitendra Malik ECCV, 2012 supplement / bibtex / poster / video This paper is subsumed by SIRFS. |


|
Jonathan T. Barron, Jitendra Malik CVPR, 2012 supplement / bibtex / poster This paper is subsumed by SIRFS. |

|
Allison Janoch, Sergey Karayev, Yangqing Jia, Jonathan T. Barron, Mario Fritz, Kate Saenko, Trevor Darrell ICCV 3DRR Workshop, 2011 bibtex / "smoothing" code We present a large RGB-D dataset of indoor scenes and investigate ways to improve object detection using depth information. |

|
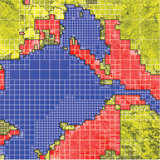
Jonathan T. Barron, Jitendra Malik CVPR, 2011 bibtex This paper is subsumed by SIRFS. |
|
Jonathan T. Barron, Jitendra Malik Technical Report, 2010 bibtex A model and feature representation that allows for sub-linear coarse-to-fine semantic segmentation. |

|
Jonathan T. Barron, Dave Golland, Nicholas J. Hay Technical Report, 2009 bibtex Markov Decision Problems which lie in a low-dimensional latent space can be decomposed, allowing modified RL algorithms to run orders of magnitude faster in parallel. |

|
Jonathan T. Barron, David W. Hogg, Dustin Lang, Sam Roweis The Astronomical Journal, 136, 2008 Using the relative motions of stars we can accurately estimate the date of origin of historical astronomical images. |

|
Jonathan T. Barron, Christopher Stumm, David W. Hogg, Dustin Lang, Sam Roweis The Astronomical Journal, 135, 2008 We use computer vision techniques to identify and remove diffraction spikes and reflection halos in the USNO-B Catalog. In use at Astrometry.net |
|
|


|
Feel free to steal this website's source code,
just add a link back to my website.
If you'd like your new page linked to from here, submit a pull request adding yourself or send me an email with a link.
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
✩
|